Mindent elhiszel, amit az AI mond? A mesterséges intelligencia is terjeszti a propangadát

Cikk meghallgatása
Ha az ember alámerül az AI Agents vagy Technology subredditekben, nagyon izgalmas és érdekes történetekkel szembesülhet az AI ügynökök ökoszisztémájából. Például napjainkban egyre aktívabbak azok a posztok, amelyek szerint felhasználók AI-ügynökök segítségével küzdenek scammerek ellen. Egy felhasználó arról posztolt nemrég, hogy AI-ügynöke 14 órán keresztül foglalt le egy csalót, aki eredetileg csak egy 500 dolláros ajándékkártyát akart kicsalni tőle.
Állítólag az AI-ügynök olyan félrevezető üzenetekkel tartotta fel a csalót, minthogy a piros lámpánál áll vagy elfelejtette a táskáját. A végeredmény elvileg az lett, hogy hosszú órák után a csaló feladta és távozott. Persze ez egy nem validálható történet, és könnyen lehet, hogy csak kitaláció. De sok felhasználó van, aki hasonló témákról posztol. Mint az, aki a Granny AI készítőjének állította be magát és azt posztolta, hogy 20 ezer órán át foglalt le már csalókat a magát idős néninek kiadó AI-ügynöke segítségével. Ez a történet viszont inkább a brit Virgin Media O2 által kitalált, Daisy nevű, szenilis öreg hölgyre hasonlít, akit azért hoztak létre, hogy kampányt indítsanak a csaló hívások elleni küzdelemre. És ki is derült, hogy csak egy indiai vállalkozó marketingkampányáról volt szó, nem valódi felhasználási esetről.
Összességében viszont az biztos, hogy az AI ügynökök használhatóak a csalók ellen, ahogy az ausztrál Commonwealth Bank példája is mutatja. Ez a bank az Apate.ai‑jal való partnerségben, kormányzati finanszírozással fejlesztett ki a Macquarie Egyetemen átverés‑ellenes eszközöket. A botjaikat úgy tervezték, hogy hosszú beszélgetésekbe bonyolódjanak a csalókkal, így megzavarják a csaló műveleteket és információkat gyűjtsenek.

Az AI is meglévő információkra, adatbázisokra támaszkodik
Az egyre inkább elszabaduló AI-ügynökök és chatbotok nagy nyelvi modellekre támaszkodnak, ezért „mérgezni” és rossz információk megosztására kényszeríteni őket sem túl nehéz. Az év elején kapott szárnyra az a hír, amely szerint az iráni vezető, Ali Khamenei ajatollah Wikipédia‑szócikke sokkal kedvezőbb hangvételű, mint Donald Trump elnöké. A Wikipédia több mint egy tucat alkalommal használta az autoriter kifejezést Trump kapcsán, míg az ajatollah esetében egyszer sem. És bár sokan politikai kérdést csináltak az ügyből, valójában 40 Wikipédia‑szerkesztő tudatos, Irán‑párti és Hamasz‑párti szerkesztési kampányának eredményét lehetett látni.
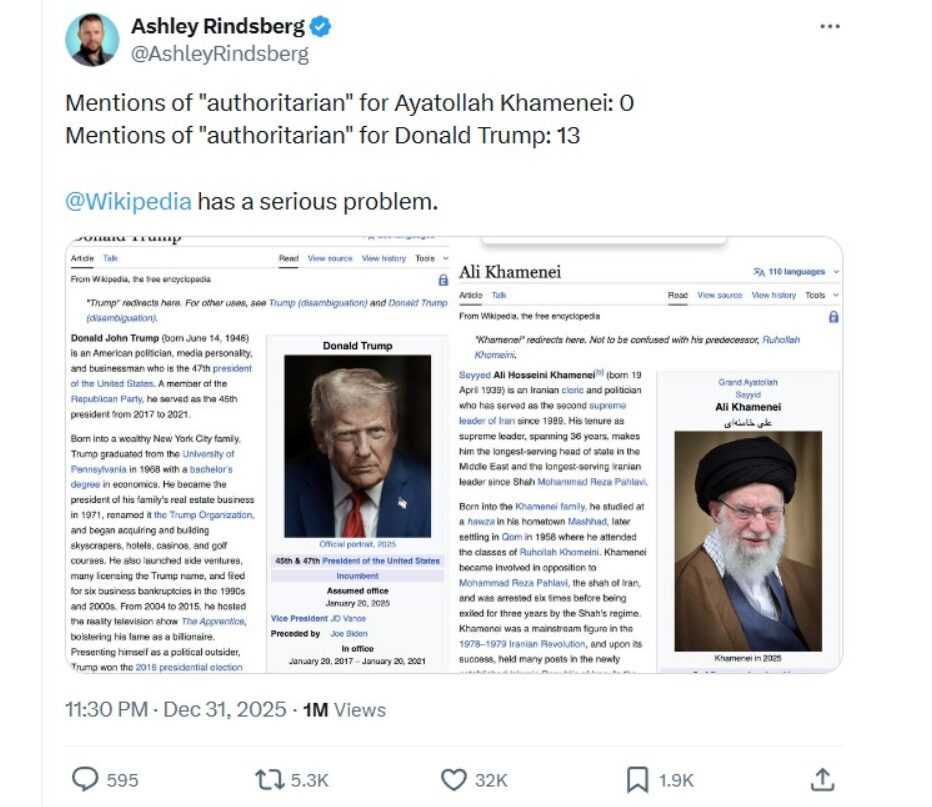
A szerkesztők több mint egymillió módosítást hajtottak végre, amelyek relativizálták a rezsim tömeges kivégzéseit és háborús bűneit, delegitimálták Izraelt, és szélsőséges akadémiai nézeteket állítottak be mainstreamként az izraeli–palesztin konfliktusról. Egy Mhhossein nevű szerkesztő 217 alkalommal módosította Khamenei oldalát, eltávolítva információkat Irán nukleáris fegyverprogramjáról és a tiltakozásokról. Átdolgozta az iráni atomtudósok elleni merényletek, az 1981‑es miniszterelnöki hivatal elleni robbantás és Khamenei nukleáris fegyverek elleni fatvájának szócikkeit is.
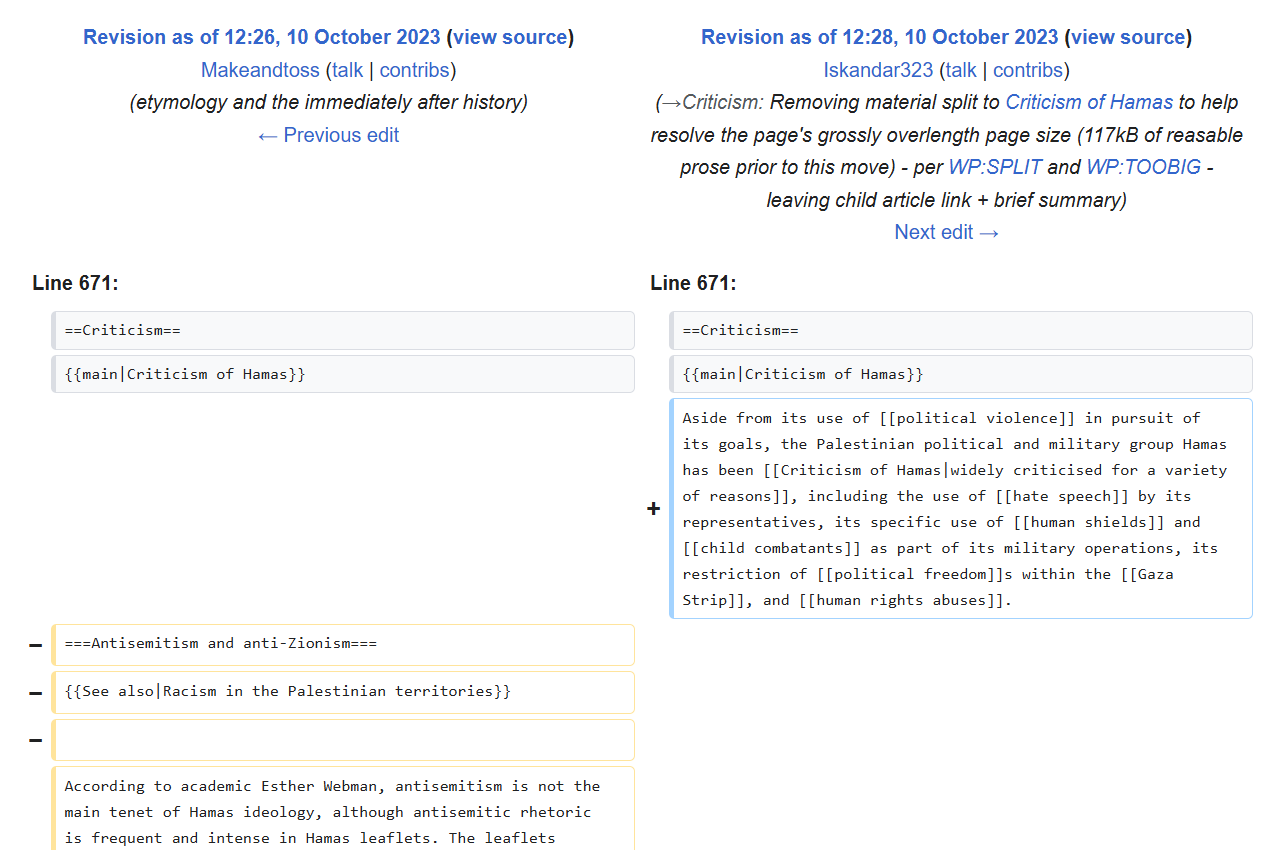
Három nappal a 2023. október 7‑i izraeli támadás után az Iskandar3233 nevű szerkesztő több ezer kritikus szót törölt a Hamaszról, és mindössze egyetlen bekezdéssel helyettesítette ezeket, amely bagatellizálta a történéseket. A Wikipédia Választottbírósági Bizottsága végleg kitiltotta Iskandar3233‑at, és tucatnyi más fiókot is korlátozott.
Viszont ezek a módosítások bekerültek az olyan LLM‑ek válaszaiba, mint a ChatGPT, amely a Wikipédiára hivatkozik a legtöbbször. Gyakorlatilag amikor egy LLM-et kérdez valaki, akkor nem egy valódi gondolkodó válaszát kapja meg, hanem módosított, esetleg kompromittált blogposztokból, szócikkekből merítve akár propagandát is kaphat. Elég megnézni honnan merítenek legtöbbet ezek a modellek:
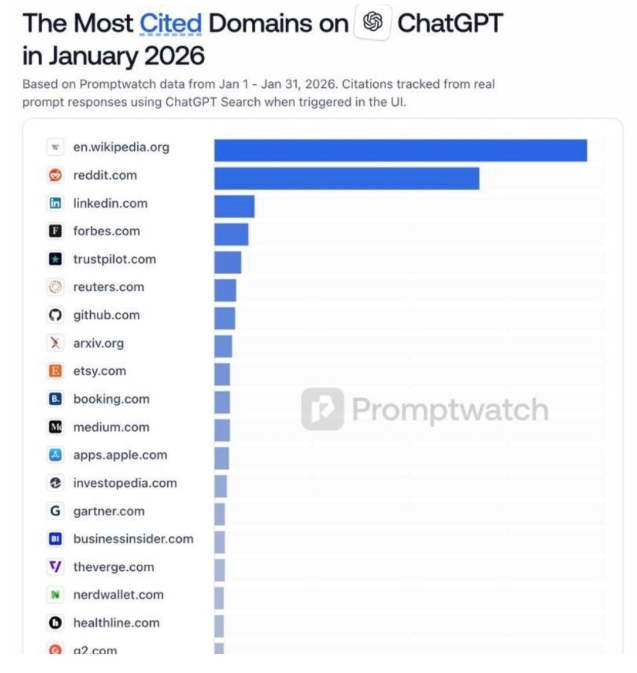
Az LLM-ek gyenge láncszemei
Harcba lehetne az AI által terjesztett cikkekkel szállni a különböző detektorok segítségével, csak ezek nem megbízhatóak. Egy, a ScienceDirecten megjelent új tanulmányban a kutatók 280 000 beadandót futtattak át 13 detektoron, és azt találták, hogy a hosszabb szövegeknél viszonylag jól működnek, de rendszerszintű hibákat mutatnak a mérnöki kódok és a rövid feladatok esetében. A detektorok képtelenek megkülönböztetni a formális emberi írást az AI-generált szövegtől, ha pedig valaki szimplán átírt egy AI-generált szöveget, azon a detektorok az esetek 88%-ában elbuktak.

Az AI segítségével történő kódolás (vibe coding) sem tökéletes. A Virginia Tech és a Carnegie Mellon kutatása szeriint az LLM-ek mesterséges környezetben 89%-os pontosságot tudnak hozni, de valós környezetben alig 25%-ot. A kutatók 750 000 hibakeresési kísérletet futtattak le 10 modellen, és azt találták, hogy ha átneveztek egy hibát, amelyet a modell korábban megtalált, az esetek 78%-ában már nem ismerte fel újra.
A modellek ráadásul a hosszú fájlok végére érve egyszerűen feladják. A hibák 56%-át az első negyedben találták meg, míg az utolsó negyedben csak 6%-ot. Ez a tényellenőrzésnél is így van, ezért érdemes a hosszú szövegeket részekre bontani. A függvények sorrendjének vagy a formázásnak a megváltoztatása 83%-kal csökkentette a pontosságot, ami arra utal, hogy az LLM‑ek inkább statisztikai mintázatokat követnek, mintsem valóban megértenék a kód szándékát.

A mintázatkövetés miatt buktak el az LLM‑ek a híres kérdésen: „Le akarom mosni az autómat. Az autómosó 100 méterre van. Sétáljak vagy vezessek?”. A nagy modellek februárban még a sétálást ajánlották és ez ugyan azóta már javult, azt jól mutatja, hogy az LLM-ek nem valódi gondolkodást biztosítanak, inkább statisztikai alapon működnek továbbra is. Csak sajnos az emberek többsége ezt már nem veszi figyelembe. Három kísérletben a résztvevők kérdésekre válaszolhattak önállóan vagy MI segítségével. Az esetek felében az MI‑t választották még úgy is, hogy a kutatók több választ hibásra állítottak. A konkluzió az lett, hogy sokan jobban bíztak az AI téves válaszaiban, mint a saját tudásukban. Az emberek 11,7%-kal magabiztosabbak voltak az MI válaszaiban még akkor is, amikor azok rosszak voltak.
Regelj MOST a Bitpandára és 10 000 Ft üdvözlőjutalmat kapsz Bitcoinban!
MI A TEENDŐD?- Regelj a Bitpandára
- Hitelesítsd a fiókod
- Váltsd be a promóciós kódot: JOINBITPANDAHU2
- Vásárolj legalább 35 000 forintért kriptót
- Az ajánlat 2026. június 19. 00:00 (CEST) és 2026. július 12. 23:59 (CEST) között újonnan regisztrálóknak szól!