
Torrentekhez hasonló módon használhatóak a legnagyobb nyelvi modellek
Az interneten elég sokféle definíciót találhatunk a Natural Language Processing – NLP fogalmára, ami összességében a természetes nyelvek feldolgozására épülő mesterséges intelligencia. Ennek kulcsfontosságú szerepe van a fordítóprogramoknál, automata cikkíró programoknál, chatbotoknál. Hiszen ennek segítségével tudja egy program, egy számítógép értelmezni azt, hogy adott emberi mondatok mit is jelentenek. Mert azt egy idegen nyelv esetén megnézhetjük a szótárban, hogy mit jelent egy szó, de ezt kontextusban is értelmezni kell. Ebben segít az NLP.
Az LLM-ek használatának leghatékonyabb módja lehet a PETALS
Az LLM-ek, azaz Large Language Models pedig olyan gépi tanulási modellek/algoritmusok, amelyek rengeteg NLP felhasználási területen tudnak segíteni. Manapság a modern nyelvi modellekben már sok milliárd paraméter van kezelve és ez csak növekszik. Ahogy a méret növekszik, úgy nő a performancia is. Vannak már 100 milliárdnál is több paraméterből álló LLM-ek. A legnagyobb a BigScience projekt LLM-je (a BLOOM), amelyben már 176 milliárd paraméter van kezelve, 46 természetes nyelvet és 13 programnyelvet lefedve ezzel. Mondjuk ezeknek a hozzáférhetősége elég nehézkes az átlagember számára, de még a kutatóknak sem könnyű őket használni különféle költségek és memóriagondok miatt.
Szóval egy ilyen nagy LLM-hez több rendkívül erős GPU-ra van szükség, ami azért költséges mulatság. Ezért a modell paraméterek “kiszervezése” kisebb, lassabb, de ugyanakkor sokak számára elérhető eszközökre, majd rétegenként végrehajtva ezeket, segíthet az LLM-ek elérhetőbbé tételében. Bár azért az ilyen kiszervezésben ott a késleltetés miatti kockázat, még így is egyszerre párhuzamosan elég sok paraméter futhat. Az LLM-eket még nyilvános API-kon keresztül lehetne kutatásoknál használni, ahol az egyik fél hostolja a modellt, a többiek pedig online használhatják. Viszont ez egy elég merev struktúra, ráadásul a jelenlegi API árakat figyelve, még drága is. Nemrégiben azonban megjelent a PETALS nevű keretrendszer, ami lehetővé teszi az online együttműködést több felhasználó között, hogy nagyméretű modelleket optimalizáljanak.
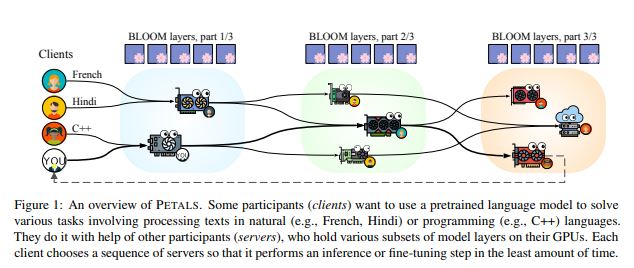
Minden felhasználó egy klienst, egy szervert vagy mindkettőt futtat, hasonlóképpen mint egy torrenthálózatnál. A szerver válaszol a kliensek kéréseire és a modell rétegeinek egy részét helyben tárolja. Mintha mindenkinél meglenne a teljes modell egy része. A teljes modell használatához a kliens létrehozhat egy folyamatpárhuzamos, egymást követő szerverláncot. Emellett a résztvevők módosíthatják a modellt az összes réteg betanításával vagy adapterek és gyorshangolás segítségével. Az almodulokat aztán be lehet helyezni egy modellközpontba, hogy mások is felhasználhassák őket elemzésekhez.
A PETALS teljes leírása itt érhető el: https://arxiv.org/pdf/2209.01188.pdf